Making of Literary Constellations
By Nicholas Rougeux, posted on January 15, 2017 in Art, Data
Literary Constellations is a series of posters designed to resemble constellation maps but instead of being based on real stars, the shapes are based on first sentences from chapters of short classic stories.
Since creating Number Walks, I wanted to use the concept of wandering paths based on data for another project. I love the unpredictable paths created by looking at data this way. I enjoy using classic literature as the data because it’s so easily available and open to interpretation from a number of viewpoints. Proper grammar was big part of my childhood. With a mother as a financial editor and a father as an English teacher, it was unavoidable but also something for which I developed a special affinity.
I decided to find a way to visualize the opening lines of classic literature based on parts of speech. My first idea was to use the opening lines of famous novels and made an initial attempts were with the opening lines of Jane Austen novels. Using Project Gutenberg, I collected the opening lines and classified each word. Then the data was imported into NodeBox where circles were drawn—assigning angles and colors based on parts of speech. Circles and lines following them were also based on word lengths.
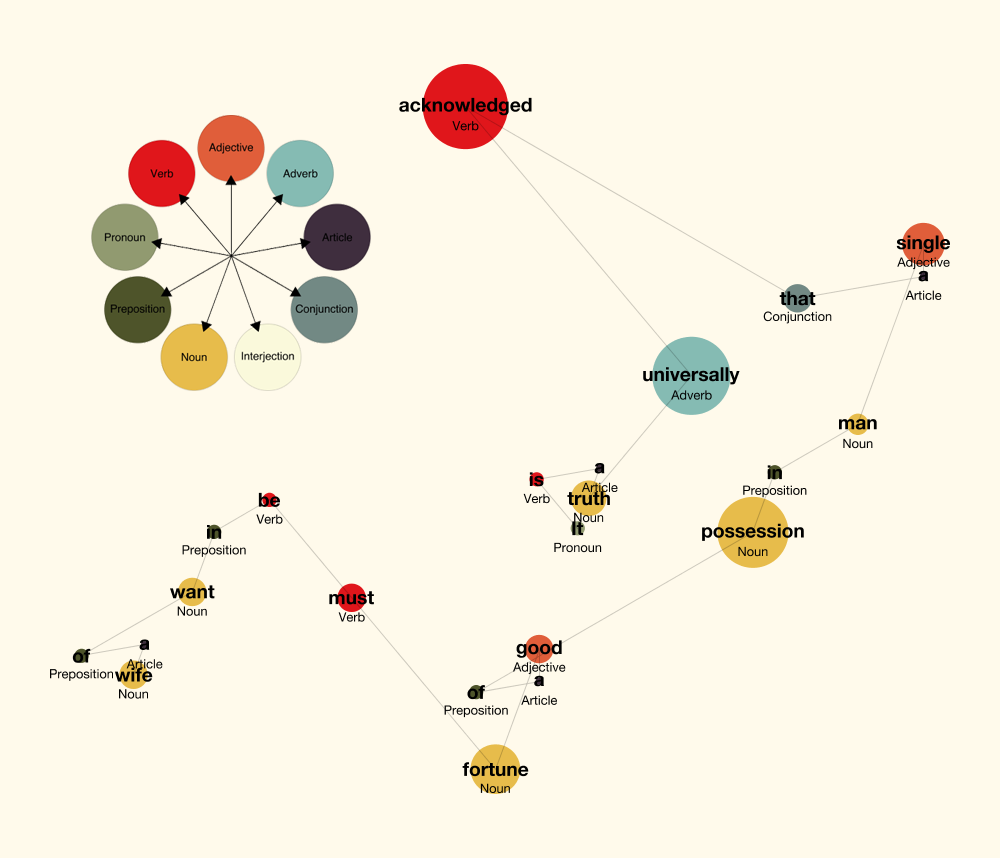
First sentence of Pride and Prejudice by Jane Austen, “It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.”

First sentences of Jane Austen’s six published books: 1. Northanger Abbey, 2. Pride and Prejudice, 3. Persuasion, 4. Mansfield Park, 5. Sense and Sensibility, 6. Emma
The early NodeBox configurations were fairly messy but early ideas usually are:
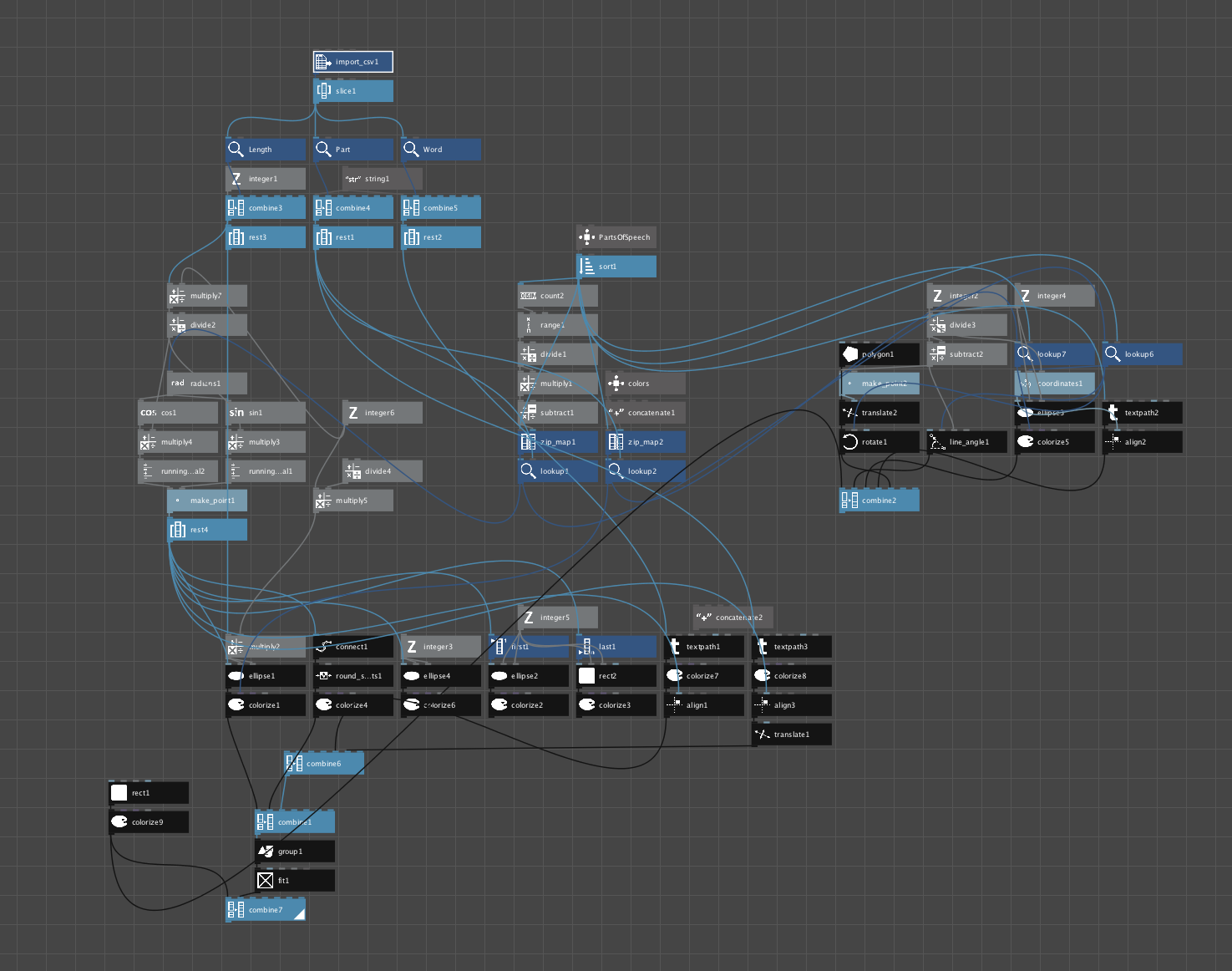
NodeBox configuration for generating the previous graphics. The left majority of nodes parse data for one opening line and the cluster on the right is for generating the parts of speech legend.
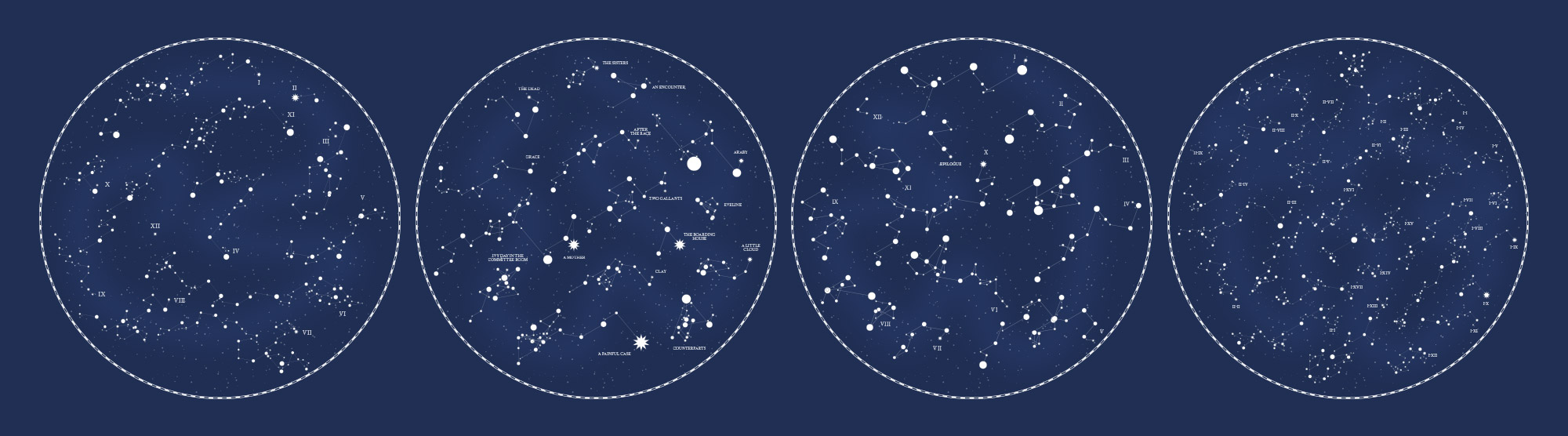
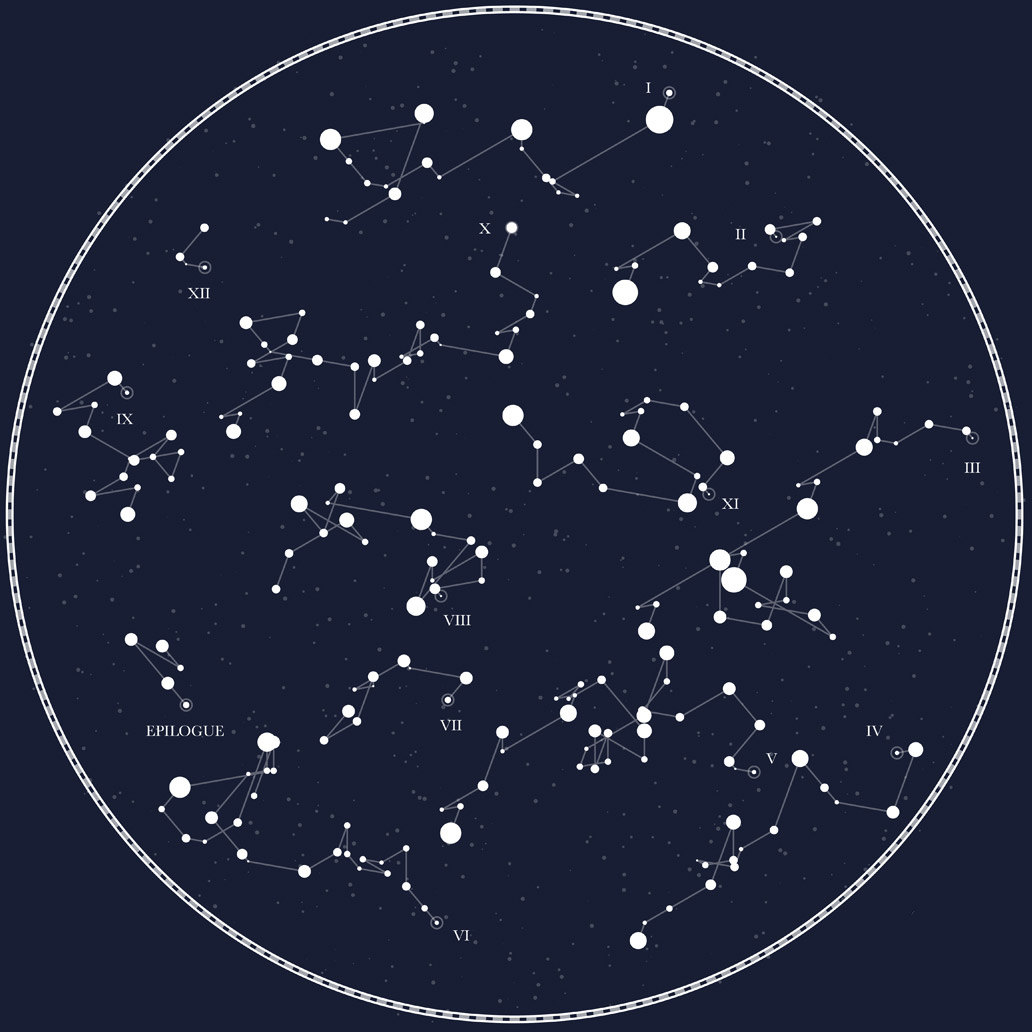
I didn’t intend to create constellations. I just wanted an interesting visual way of looking at text but quickly found that what I was creating resembled constellation maps so I decided to explore that idea by creating one based on not just the opening lines of entire books but the opening lines of each chapter in books. I started with The Time Machine by H. G. Wells.
Each chapter was also arranged by hand because NodeBox doesn’t have the capability of positioning them in an efficient way to fill the available space. So NodeBox was used to create the initial paths, which were arranged by hand in Illustrator in the circular shape.

Raw export from NodeBox
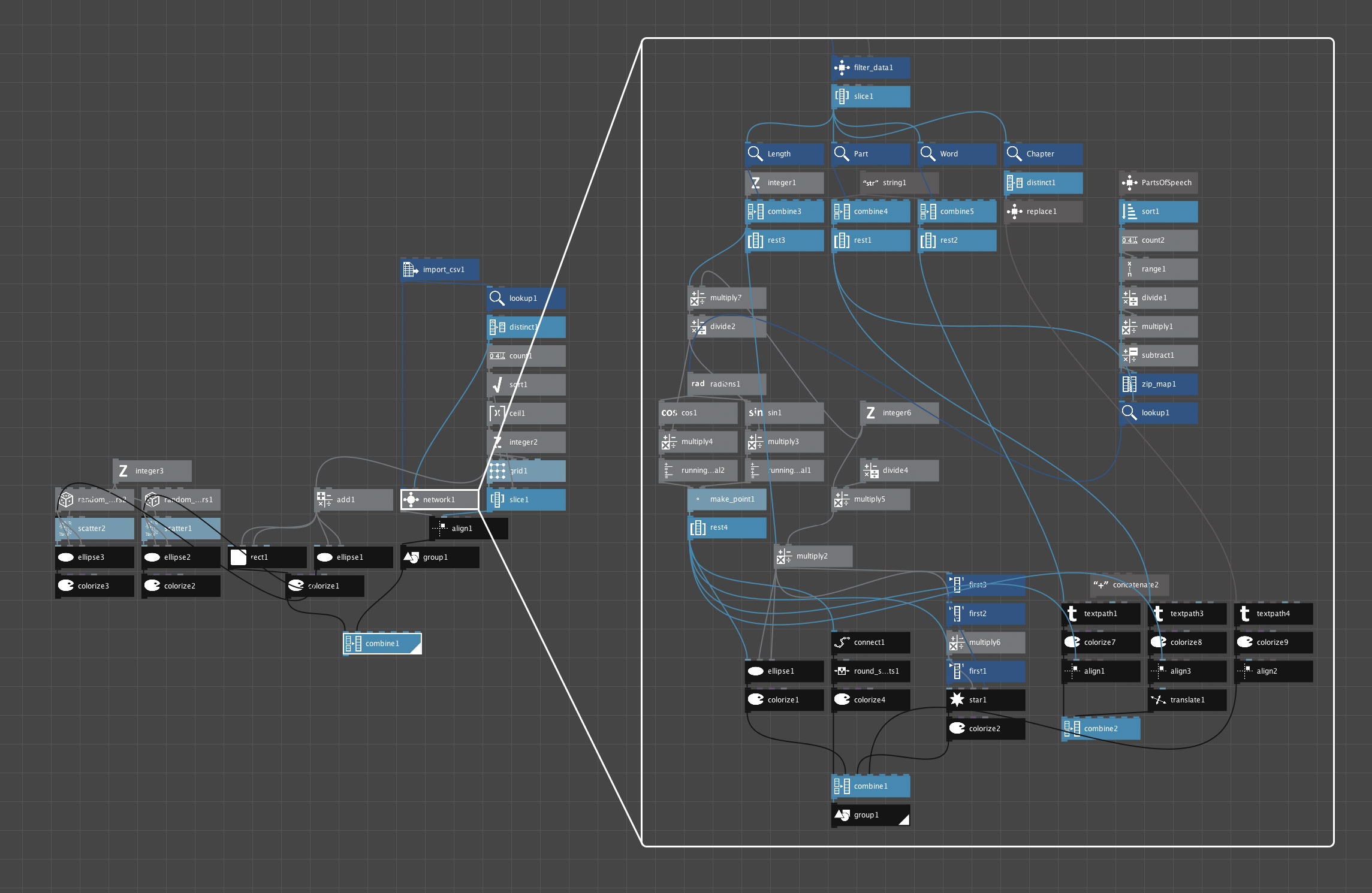
Final NodeBox configuration
Early concept of The Time Machine
I really enjoyed how it turned out with the few extra flourishes such as a decorative border the extra stars in the background, chapter numbers, and highlighting the first word of each chapter with a different style of “star.”
After a lot of polishing and correcting how the data was parsed, this is the final style of the posters—including a legend, the text of each first line, and a faint highlight connecting each chapter loosely resembling the galaxy “cloud” often seen in constellation maps.

Final poster for The Time Machine
The final set of posters includes classic stories like Alice’s Adventures in Wonderland, Dubliners, The War of the Worlds, and more. I found that stories with around 10–20 chapters work best in this design. Those with fewer result in an emptier poster and those with much more become impossible to read.
I’m very pleased with the final result. Is it analytical or informative? No, but it does provide a new and interesting way to look at classic literature.
